Edit this page with Git
About
Development of the plugin started with the idea to load data into software as data dependencies, in a similar manner that Maven can load software dependencies automatically via Maven Central and Archiva. Initially, we started with this plugin and implemented all features here. Now the Databus Website exists and the concept of Databus Mods as well as the Databus Client. Therefore we are slimming down this plugin in the following manner:
dataid.ttl stays stable as an interface. If the Databus Maven Plugin is thinner, it is easier to implement in other programming languages.- file statistics will be calculated by Mods, see Databus Download for a detailed
dataid.ttl description (also how to query it) and a list of planned changes, as they might break queries.
- Mods also take the role of validating and testing files
- A lot of format interoperability and conversions issues are now covered via the Download Client
- License of the client might become more permissive soon -> Apache
Security notice
- We are currently using a combination of DBpedia Keycloak Single Sign On for user registration and front end service and WebID profiles with private keys for file and DataID signing.
- The main problem we are facing is that via the Databus we are trying to automate all processes on servers with cronjobs. Therefore, they require either private keys with no passwords or to add the password to a config file. All of our servers are shared between multiple root developers, so honestly all of the Databus developers have access to all other private keys and accounts. We are investigating how to manage signatures either client-side via browser certificate, or by integrating them into our https://www.keycloak.org/ server, which we also use for https://forum.dbpedia.org
- as a take-away message: yes, WebID is secure, if the space where you host the
.ttl is secure and if you have good local security and are the only root admin or trust all other admins.
Introduction
Databus is a Digital Factory Platform and transforms data pipelines into data networks. The databus-maven-plugin is the current CLI to generate metadata about datasets and then upload this metadata, so that anybody can query, download, derive and build applications with this data via the Databus. It follows a strict Knowledge Engineering methodology, so in comparison to BigData, Data Science and any Git-for-data, we implemented well-engineered processes that are repeatable, transparent and have a favourable cost-benefit ratio:
- repeatable: data is uploaded using a modified software methodology from Maven and Maven Central; loading can be configured like a data dependency, so your software will not break
- transparent: uploaders sign their metadata, no license unclarity, provenance on dataset-version-level
Overview
- FAQ
- Databus Operations - A high-level explanation
- Implementing the methodology - A practical guide with Use Cases
- Technical Manual
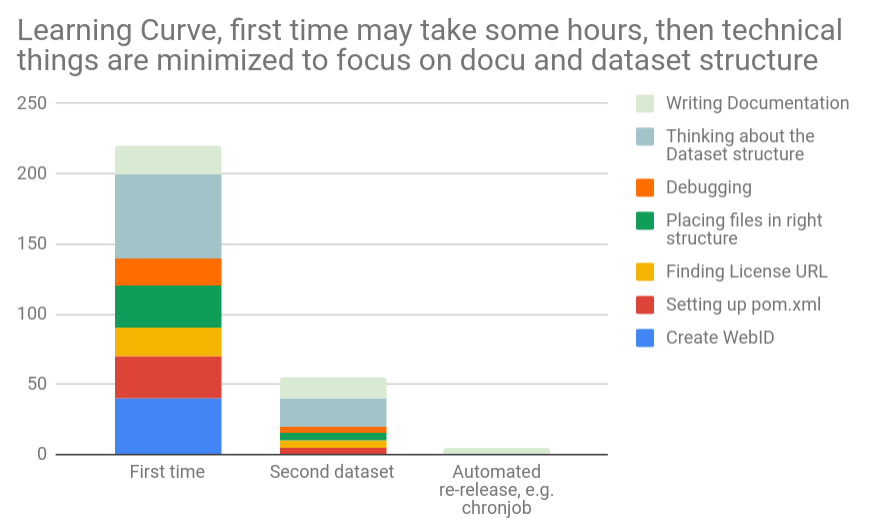
FAQ
- Do I need to read the whole manual? Not really, just go to technical setup and follow the steps and copy from existing examples. Also, there are some Use Cases in the Implementing the Methodology section.
- Do I need to download and compile code? No! All the code is precompiled, installing maven and configuring the pom.xml is enough. Maven is a build automation tool, downloading all the code, so it can be executed.
- Do I need to learn Maven? - No, we wrote a plugin that should automate most of the things, Maven is an automation build tool with very good CLI and Config Options. You will need to define properties in an XML file and run
mvn with options on CLI like it were any other software that you configure and then execute.
- I encountered a problem / I am stuck - There is a troubleshooting guide at the end of the README, if you think it is a technical problem, please use the issue tracker.
- How do I join the development team? - via the DBpedia Forum or Slack
- Is it possible to write my own client in haskell or python? - The upload to databus is a HTTP Multipart POST with three parameters and simple. The main work is to generate all the metadata correctly. We are working on a SHACL spec for the dataid file, which can aid in validating third-party client produced metadata.
- How is all that data hosted? The Databus SPARQL API indexes the generated metadata only, which is quite small (~20 triples per file). The data itself must be hosted on the publisher side. Note that file hosting is very cheap in comparison to keeping Linked Data, a REST-API or a live database running and static file publication is less susceptible to Link Rot
- Is it secure? Below is a section on security. If questions remain, please create an issue.
- Is it for open data only? No, it creates incentives for publishing open data, as you can follow the
derive and describe links and deploy tons of applications automatically. However, you can put a password in front of your data and charge for access as well.
- Can I deploy it in my organisation? Yes, we offer support to deploy the Databus server and the maven plugin inside your org with the data and metadata not leaving your premises.
Databus Operations (a high-level explanation)
The Databus solves fundamental problems of data management processes in a decentralised network. Each new release is a workflow step in a global network consisting of Load-Derive-Release. Data is downloaded based on the Databus metadata, derived and re-published.
- load browse the Databus and collect dataset for downloading like a software dependency
- derive build applications, AI or transformations
- release the data again using this maven plugin
The best example is DBpedia itself, where we load the Wikimedia dumps, derive RDF with the extraction framework and release the data on our server and metadata on the databus. Other users repeat this procedure.
Operation Load
Operation Derive
Operation Describe
Operation Release (Package & Deploy)
The main purpose of the Databus Maven Plugin. Data has been loaded and processed locally and is now available in files again. These files are made accessible on the web (package) and automatically retrievable by Databus metadata (deploy).
Dataset Structure
Databus uses a mix of several concepts that have proven successful:
Authentication and Security
The Maven Plugin uses client certificate (.X509) authentication to establish HTTPS and private key signatures of the data files and metadata.
Publishers are required to keep their own private key/.X509 bundle, which they use to:
- Sign the data files
- Sign the
dataid.ttl metadata file
- establish the HTTPS connection
- proof the existence of a Databus Account linked to the WebID profile using this key pair (check
curl https://databus.dbpedia.org/system/api/accounts
- POST 1 and 2
Private keys are like passwords. The publisher is responsible for due diligence (don’t loose, don’t share)
In addition, publishers are required to publish their public key on their servers as a WebID such as http://webid.dbpedia.org/webid.ttl#this .
Clients can verify the signature of files against the publisher’s public key, either by retrieving the public key from the webid or via this query (the SPARQL API caches all webids on a daily basis):
PREFIX dataid: <http://dataid.dbpedia.org/ns/core#>
PREFIX dct: <http://purl.org/dc/terms/>
PREFIX dcat: <http://www.w3.org/ns/dcat#>
PREFIX cert: <http://www.w3.org/ns/auth/cert#>
# Get all files
SELECT DISTINCT ?file ?publisher ?publickey ?signature WHERE {
?dataset dataid:artifact <https://databus.dbpedia.org/dbpedia/mappings/geo-coordinates-mappingbased> .
?dataset dcat:distribution ?distribution .
?distribution dcat:downloadURL ?file .
?distribution dct:publisher ?publisher .
?publisher cert:key [ cert:modulus ?publickey ] .
?distribution dataid:signature ?signature .
}
Implementing the methodology - A practical guide
The Databus prescribes a minimal structure to bring order into datasets, beyond this the decisions on how to use it, stay with the publisher. Below is a set of decisions that need to be taken.
Use Cases for different dataset structures
The basis for any data publication on the bus are files, which are grouped into versions and then artifacts. The main aspect, that should drive dataset structure is the potential users with two basic rules:
- Users would expect that a new version of the same artifact will behave like older versions, i.e. contains the same kind of files regarding number, content, format and compression.
- Any breaking and non-breaking changes are documented in the changelog.
and as a practical tip:
- If you are duplicating a lot of documentation (i.e. changelogs, dataset description, etc.) you might need to adjust the groups or artifacts.
However, we advise against breaking changes as a new artifact can be created. Below are some use cases as a template to design artifacts. In complex cases, it might be helpful to read about Maven’s Inheritance vs. Aggregation.
DBpedia Releases
In its core DBpedia has 4 different kind of extractions: Generic (19 artifacts), Mappingbased (6 artifacts), Text (2 artifacts) and Wikidata (18 artifacts), which each have their special dependencies and ways to run and set up. Hence we created four different groups with different group metadata (e.g. text has a different license). This way, we can run them individually on different servers. Furthermore, the artifacts relate approximately to one piece of the code, e.g. Label Extractor extracts Generic/Labels. In this manner, the produced data is directly linked to the code and also run together in an adequate way (not too small, as too much setup is required, but also not too big, i.e. it would take 8-12 weeks to run all extractions on one server, but only 2 days to run only the mappings group).
Some artifacts are produced in 130 languages. However, it would have been very impractical to create 130 artifacts as documentation would be copy/paste, so we encoded language as a contentvariant in the file name lang=en, which increases the number of files per artifact, but keeps the overall massive data publication process manageable.
In addition to this, we have a clean contribution process. DBpedia contributors release data in their space like Marvin on an extraction server and we quality check it before downloading from his databus space on our server and re-releasing under DBpedia.
Link contribution to DBpedia
We have several organisations and individuals that are contributing links to DBpedia. We are currently preparing a working example and will link it here later.
Most of them, however, have a single artifact called links with a file links.nt.bz2 and produce new versions infrequently. Some publish tsv files, where small converters filter and derive an RDF version upon release.
PDF to JSON to Knowledge Graph (internal)
In an industrial environment, we have implemented the Databus in the following way:
A customer sends PDF documents for digitalisation of data about 10k different machines . There are several documents from different contexts (maintenance report, certification, etc.) for each machine. Upon receipt, all the relevant files for one machine are loaded into one artifact with the machine identifier, e.g. M2133. Each context is encoded as a contentvariant, so per artifact there are 4 files: M2133_maintenance.pdf, M2133_certificate.pdf, etc. Since the same files are sent each year for each machine in a different week, the files are packaged on a local server and deployed to the SPARQL API on an artifact basis within the PDF group
The OCR and NLP tools scan the SPARQL API twice each day. As soon as they find new versions, they begin extracting facts and save them as a JSON file using the same articaft Ids, but in the JSON group and package and deploy them including the prov:wasDerivedFrom to the PDF group/artifact/version.
The JSON to RDF converter scans the SPARQL API as well and also has individually versioned artifacts.
The main reason to separate these three cycles here is that each of them is executed by a different department. During the RDF conversion, we implemented SHACL and other tests, which report issues alongside the RDF releases. These can be queried via the SPARQL API as well and are treated as issues for the OCR/NLP extraction group as upstream feedback. In this manner, the provenance is very granular, however the versioning and release process is more complex. A changelog is kept
Extracting data from MCloud and converting it to RDF
coming soon
Co-evolution of own ontology and data with DBpedia
In the semantic web interoperability is achieved by co-evolution of own data with DBpedia. This mean linking entities to DBpedia identifiers and mapping ontologies to the DBpedia Ontology and other Vocabularies.
The basic setup for such a project is to:
- configure a collection for the DBpedia data that your project requires and save the SPARQL query
- create an artifact for each ontology that is developed in the project.
- create an artifact for each dataset from the project
In the beginning, when the own ontology and data changes a lot, the version can be set to <version>0000-initial-dev<\version> and overwritten each time the data is used internally. Later the data processes should be automated and versions should increase.
When it is sufficiently stable the linking can be automated in the following way:
- create a collection for your data and ontologies
- download the DBpedia collection into a SPARQL Database docker
- download the project data collection into a SPARQL Database docker
- configure a linking tool like Limes or SILK to work on both dockers
- create a linking artifact to release the links as an own dataset and add them to the final collection
This setup automates the alignment to DBpedia.
Adjusting release cycle and version
NOTE: version MUST NOT contain any of these characters \/:"<>|?* as they conflict with maven and URIs and filenames.
The main decision to take here is how often the files are released. This can differ widely according to the use case. In general the <version> is a free field, so you can use arbitrary names like <version>dev-snapshot</version>. We also allow re-releases of same versions at the moment, so it is possible to re-release dev-snapshot according to your development needs, i.e. one person from the team shapes and tinkers on the data and re-releases 2-4 times per workday, the other person re-downloads and tests it. It is also possible to add minutes to the version string 2019.01.05-14.09 or 2019.01.05T14.07.01Z, if you need to keep track of development history of the data. Please be considerate of these two facts:
- overwriting old versions is fine, but every time you create a new version around 100KB metadata will be saved on our server, which is around 6MB per minute or 8GB per day, if there is one release per second. Please contact us in advance if you plan to release with high frequency on a daily basis.
- Metadata is stored in a SPARQL/SQL database, which uses
ORDER BY DESC on the version string. Any queries asking for the highest version numbers are sorted alpha-numerically, meaning <version>ZZZZZZZZ</version> will almost always be shown as the latest version. The user has the freedom and the responsibility to choose versions accordingly.
Guideline: The publisher should not be burdened with providing additional formats
A dedicated download client has not been written yet, but isomorphic derivations of the data can be done during download. We distinguish between format - and compression variants. A simple example how to download as NTriples/bzip2 as RDFXML/GZip:
FILES=`curl "https://databus.dbpedia.org/repo/sparql?default-graph-uri=&query=PREFIX+dataid%3A+%3Chttp%3A%2F%2Fdataid.dbpedia.org%2Fns%2Fcore%23%3E%0D%0APREFIX+dct%3A+%3Chttp%3A%2F%2Fpurl.org%2Fdc%2Fterms%2F%3E%0D%0APREFIX+dcat%3A++%3Chttp%3A%2F%2Fwww.w3.org%2Fns%2Fdcat%23%3E%0D%0A%0D%0A%23+Get+all+files%0D%0ASELECT+DISTINCT+%3Ffile+WHERE+%7B%0D%0A%09%3Fdataset+dataid%3Aartifact+%3Chttps%3A%2F%2Fdatabus.dbpedia.org%2Fdbpedia%2Fmappings%2Fgeo-coordinates-mappingbased%3E+.%0D%0A%09%3Fdataset+dcat%3Adistribution+%3Fdistribution+.%0D%0A%09%3Fdistribution+dcat%3AdownloadURL+%3Ffile+.%0D%0A%7D%0D%0ALimit+1&format=text%2Ftab-separated-values&timeout=0&debug=on"`
for f in `echo ${FILES}| sed 's/"//g'` ; do
curl $f | lbzip2 -dc | rapper -i turtle -o rdfxml -O - - file | gzip > /tmp/downloadedfile.rdf.gz
done
The directive here is to outsource the easy conversion operations to the download client upon download, which accounts for compression, simple format conversions, but also more sophisticated operations such as loading the data directly into a database (e.g. RDF into Virtuoso or HDT ) and furthermore downloading complex mappings along with the SPARQL query to use RML or vocabulary rewrite operations, e.g. download schema.org data as DBpedia Ontology.
However, these mappings and tools will be provided by third parties and should not burden the publisher.
Technical Manual
Setup
- Step 1: fulfill the prerequisites
- Step 2: create a parent pom.xml (best by copying this example
- Step 3: create artifact folders, artifact pom.xml and the .md documentation files (again see the example)
- Step 4: rename your files and copy them into the version folders of each artifact
- Step 5: run
mvn validate
Prerequisites
1. Install Maven higher than 3.3.9
- Note that any version higher than 3.0 should work, but we tested it with 3.3.9
- Ubuntu
sudo apt-get install maven
- Windows installation
Check with mvn --version
2. Create a WebID and a PKCS12 (.pfx) file
The WebID tutorial is here: https://github.com/dbpedia/webid#webid
Note: The WebID MUST be hosted on a server supporting HTTPS
3. Create a DBpedia Databus Account
Go to Databus Website and click Register to register for a new account via email or click Login and select GitHub to use your existing GitHub account name and credentials for authentication.
4. Link Databus Account to your WebID
Once you have a verified account, login to your Databus account and enter your WebID under Account > WebID URI field. Click Save. Note: It can take up to 30 minutes until the change will take effect on the Databus. Moreover take care that the URI begins with https://(you can verify everything worked by adapting this SPARQL query).
Security setup
Option 1 (recommended):
- adding the pfx file and password to maven settings.xml, normally located at
${user.home}/.m2/settings.xml
- copy the .pfx to the path configured in
<privateKey>
<server>
<id>databus.defaultkey</id>
<privateKey>${user.home}/.m2/certificate_generic.pfx</privateKey>
<passphrase>this is my password</passphrase>
</server>
Option 2:
- add the parameter to the parent pom.xml:
<databus.pkcs12File>${user.home}/.m2/certificate_generic.pfx</databus.pkcs12File>
- The plugin will ask you to enter the password, when you run it
- Note that you can remove the password from the .pfx file, if it is in a secure location
Directory setup
Three artifacts with one version each:
~/IdeaProjects/databus-maven-plugin/example/animals$ tree
.
├── birds
│ ├── 2018.08.15
│ │ └── birds_mockingbird.nt
│ ├── birds.md
│ └── pom.xml
├── fish
│ ├── 2018.08.15
│ │ ├── fish_mappingbased_ussorted.ttl
│ │ ├── fish_sorttest.txt
│ │ ├── fish_subspecies=carp.ttl
│ │ └── fish_subspecies=goldfish.ttl
│ ├── fish.md
│ └── pom.xml
├── mammals
│ ├── 2018.08.15
│ │ ├── mammals-2018.08.17_cat.nt
│ │ ├── mammals_binary.bin
│ │ ├── mammals_carnivore_cat.nt.patch
│ │ ├── mammals_carnivore_cat.trig
│ │ ├── mammals_monkey.nt.bz2
│ │ └── mammals.nt
│ ├── mammals.md
│ ├── pom.xml
│ └── provenance.tsv
├── pom.xml
├── test-cert-bundle.p12
└── test-cert-bundle-with-password.p12
Example 2: DBpedia Mappings dataset
Files & folders
Per default
${groupId}/
+-- pom.xml (parent pom with common metadata and current ${version}, all artifactids are listed as `<modules>` )
+-- ${artifactid1}/ (module with artifactid as datasetname)
| +-- pom.xml (dataset metadata)
| +-- ${version}/
| | *-- ${artifactid1}_cvar1.nt (distribution, contentvariance 1, formatvariance nt, compressionvariant none)
| | *-- ${artifactid1}_cvar1.csv (distribution, contentvariance 1, formatvariance csv, compressionvariant none)
| | *-- ${artifactid1}_cvar1.csv.bz2 (distribution, contentvariance 1, formatvariance csv, compressionvariant bzip)
| | *-- ${artifactid1}_cvar2.ttl (distribution, contentvariance 2, formatvariance ttl, compressionvariant none)
| | *-- ${artifactid1}_cvar2.csv (distribution, contentvariance 2, formatvariance csv, compressionvariant none)
| | *-- ${artifactid1}.csv (distribution, no content variant, formatvariance csv, compressionvariant none)
Naming scheme for files to be published
To ensure that metadata for files to be published can be determined correctly, the names of
these files have to fulfil a specific schema. This schema can be described by the following
EBNF:
inputFileName ::= fileNamePrefix contentVariant* formatExtension+? compressionExtension*
fileNamePrefix ::= [^_]+? /* a non-empty string consisting of any chars except '_' */
contentVariant ::= '_' [A-Za-z0-9]+ | '_' [A-Za-z0-9]+ '=' [A-Za-z0-9]+
formatExtension ::= '.' [A-Za-z] [A-Za-z0-9]*
compressionExtension ::= '.' ( 'bz2' | 'gz' | 'tar' | 'xz' | 'zip' )
Note: +? in the grammar above denotes a reluctant one-or-more quantifier such that, for example,
the production rule for the artifactName will not ‘parse into’ the formatExtensions when contentVariants
are absent.
Some valid filenames from the animals example from the mammals artifact:
mammals.nt - `nt` as format variant
mammals_species=carnivore_cat.nt.patch - `species=carnivore` and `cat` as content variants, `nt` and `patch` as content variants
mammals_monkey.nt.bz2 - `monkey` as content variant; `nt` as format variant; `bz2` as compression variant
mammals_cat.nt - `cat` as content variant; `nt` as format variant; `fileNamePrefix` contains a date
Invalid (counter-)examples:
mammals.zip.nt, mammals_monkey.nt.001.bz2, mammals_2018.08.17_cat.nt
As mentioned above, filenames are not only required to conform to the aforementioned schema, but the fileNamePrefix
also has to start with the name of the artifact. (Files with names starting differently will be ignored.)
Parameters explained
Version
It is highly recommended that you use the pattern YYYY.MM.DD as version
If you deviate from this, please make sure that version numbers are aplhabetically sortable, i.e.
1.10 is smaller than 1.2, so you need to use 01.10 and 01.02
in bash date +'%Y.%m.%d'
Setting the version programatically (will change version in all pom.xmls):
mvn versions:set -DnewVersion=2018.08.15
Example
Example snippet from pom.xml from Mappings, showing the common-metadata properties, you will need to describe your data.
<databus.packageDirectory>
/media/bigone/25TB/www/downloads.dbpedia.org/repo/lts/${project.groupId}/${project.artifactId}
</databus.packageDirectory>
<databus.downloadUrlPath>
https://downloads.dbpedia.org/repo/lts/${project.groupId}/${project.artifactId}/${project.version}/
</databus.downloadUrlPath>
<databus.publisher>https://webid.dbpedia.org/webid.ttl#this</databus.publisher>
<!-- moved to settings.xml
databus.pkcs12File>${user.home}/.m2/certificate_generic.pfx</databus.pkcs12File-->
<databus.maintainer>https://termilion.github.io/webid.ttl#this</databus.maintainer>
<databus.license>http://purl.oclc.org/NET/rdflicense/cc-by3.0</databus.license>
<databus.documentation><![CDATA[
documentation added to dataset using dataid:groupdocu
]]></databus.documentation>
</properties>
databus.packageDirectory
As stated above, data is hosted on your server. The packageDirectory gives the local location, where the files are copied to upon running mvn package. The following files are copied for each artifact:
- `target/databus/${version}/dataid.ttl
${artifactId}.md files- all data files in ${version}
The package can be copied to the target directory and later moved manually online:
<databus.packageDirectory>
${session.executionRootDirectory}/target/databus/repo/${project.groupId}/${project.artifactId}
</databus.packageDirectory>
When on same server, the package can be copied to /var/www directly:
<databus.packageDirectory>
/var/www/data.example.org/repo/${project.groupId}/${project.artifactId}
</databus.packageDirectory>
Also you can use the build environment as the publishing environment:
<databus.packageDirectory>
.
</databus.packageDirectory>
databus.downloadUrlPath
The command mvn prepare-package generates a turtle file with relative URIs in the target folder:
# <> is relative and expands to the file:// URL
<> a dataid:DataId ;
# internal fragment in the dataid.ttl file
<#mappingbased-literals_lang=id.ttl.bz2>
a dataid:SingleFile ;
# refers to a file in the same folder (external relative reference)
dcat:downloadURL <mappingbased-literals_lang=id.ttl.bz2> ;
Upon mvn package the dataid.ttl is copied databus.packageDirectory and all relative URIs are rewritten to:
<databus.downloadUrlPath>
https://downloads.dbpedia.org/repo/lts/${project.groupId}/${project.artifactId}/${project.version}/
</databus.downloadUrlPath>
Result (taken from http://downloads.dbpedia.org/repo/lts/mappings/mappingbased-literals/2018.12.01/dataid.ttl):
<https://downloads.dbpedia.org/repo/lts/mappings/mappingbased-literals/2018.12.01/dataid.ttl>
a dataid:DataId ;
<https://downloads.dbpedia.org/repo/lts/mappings/mappingbased-literals/2018.12.01/dataid.ttl#mappingbased-literals_lang=id.ttl.bz2>
a dataid:SingleFile ;
dcat:downloadURL <https://downloads.dbpedia.org/repo/lts/mappings/mappingbased-literals/2018.12.01/mappingbased-literals_lang=id.ttl.bz2> ;
NOTE: Don’t forget the / at the end here, if you enter #quatsch# the URIs will start with #quatsch#. This allows the necessary freedom to bend the URIs to the download location of the data.
databus.publisher
The WebId URL including #this. Used to retrieve the public key and account.
databus.maintainer
A maintainer webid, if different from publisher (normally the person doing the release).
databus.license
Pick one from here: http://rdflicense.appspot.com/
Or link your own license.
databus.documentation>
UNSTABLE, will change, see Issue 84
A <![CDATA[ ]]> field with markdown, which will be added to Dataset as dataid:groupdocu
Documentation build process:
${artifactId}.md documents the artifact
- first line will be used as rdfs:label
- Style guide: It is disadvantageous to use words like “dataset”, which is the
rdf:type already or $groupId or $publisherName, which is context. It is good to be specific about the ‘From Where?’, ‘How?’, ‘What?’, especially for ETL processes, examples:
- ’# Literals extracted with mappings’ instead of ‘DBpedia dataset with …’
- ’# Wikipedia page title as rdfs:label’
- Note: this is not strict, as sometimes it is unavoidable to use $groupid or $publisherName
- second line as
rdfs:comment
- rest as
dct:description
<databus.documentation> will be kept separate in dataid:groupdocu
Addtional parameters (used to overwrite defaults)
- databus.inputDirectory, defaultValue = “.”
- databus.pkcs12serverId, defaultValue = “databus.defaultkey”
- databus.tryVersionAsIssuedDate, defaultValue = “false” (tries to convert the version string to dct:issued)
- databus.modifiedDate, normally read from file
- databus.keepRelativeURIs, defaultValue = “false”, Dataid.ttl URIs will not be rewritten. Should only be used in a local environment.
- databus.issuedDate, normally, this is set automatically as the time, when you execute
mvn prepare-package, can be overwritten manually, format: 2019-02-07T10:08:27Z
for mvn test or mvn databus:test-data
- databus.test.allVersions, defaultValue = “false” (tests and compares all versions, version discovery is a bit hacked as it tries to guess versions based on the folder names)
- databus.test.detailed, defaultValue = “false” (tests more)
- databus.test.strict, defaultValue = “false” (fail on warning)
for mvn package or mvn databus:package-export
- (unstable planned for 1.4) databus.package.includeParseLogs, defaultValue=”false” (if true copies the parselogs into the packageDirectory)
for mvn deploy or mvn databus:deploy
- databus.deployRepoURL, defaultValue = “https://databus.dbpedia.org/repo” (The official Databus), testrepo at
<databus.deployRepoURL>https://databus.dbpedia.org/testrepo</databus.deployRepoURL>
Usage
Example
We provide a working example in the repo: https://github.com/dbpedia/databus-maven-plugin/tree/master/example/animals
All commands should work, except mvn:deploy
Use mvn -T 6 to run everything in parallel with 6 cores. The log will look messy.
Change version of all artifacts and group
mvn versions:set -DnewVersion=2018.08.15
Maven Lifecycles and Goals
Some background info, in case you would like to include scripts and other things between validate and test.
Note that we are using a super pom, which deactivates all software compilers:
<parent>
<groupId>org.dbpedia.databus</groupId>
<artifactId>super-pom</artifactId>
<version>1.3-SNAPSHOT</version>
</parent>
<!-- currently still needed to find the super-pom, once the super-pom is in maven central,
this can be removed as well -->
<repositories>
<repository>
<id>archiva.internal</id>
<name>Internal Release Repository</name>
<url>http://databus.dbpedia.org:8081/repository/internal</url>
</repository>
<repository>
<id>archiva.snapshots</id>
<name>Internal Snapshot Repository</name>
<url>http://databus.dbpedia.org:8081/repository/snapshots</url>
<snapshots>
<updatePolicy>always</updatePolicy>
</snapshots>
</repository>
</repositories>
How to make a release
Once the project is configured properly releases are easy to generate and update by typing:
Deploy is the last phase in the maven lifecycle and is the same as running:
mvn validate prepare-package package deploy
Running individuals goals
# deleting any previously generated metadata
mvn clean
# validate setup of private key/webid and some values
mvn databus:validate
# generate metadata in target/databus/dataid
mvn databus:metadata
# export the release to a local directory as given in <databus.packageDirectory>
# copies data from src, metadata and parselogs from data
mvn databus:package-export
# upload the generated metadata to the databus metadata repository
mvn databus:deploy
Run the example
There are working examples in the example folder, which you can copy and adapt.
mvn deploy will not work (no account).
# clone the repository
git clone https://github.com/dbpedia/databus-maven-plugin.git
cd databus-maven-plugin
cd example/animals
# validate, test, generate metadata and package
mvn package
# or
mvn databus:validate databus:test-data databus:metadata databus:package-export
Additional notes
TODO: deploy does a Multipart post:
- dataid.ttl
- signature of dataid.ttl
- additional parameters
